
9月19日,上海,第四届华为全联接大会,华为重磅发布通用计算和AI计算领域的最强算力产品,开放鲲鹏主板,并优先支持合作伙伴基于鲲鹏主板开发更多的计算产品,给客户更多更好的选择,共建计算产业生态,共享万亿大蓝海。
华为智能计算业务部总裁马海旭发表主题演讲
计算产业正迎来下一个黄金时代,我们在通用计算和AI计算领域坚持战略投入,持续创新,通过解决世界级计算技术难题,为世界提供最强算力。
通用计算最强算力应具备三个基本特征
我们知道,热力推动了第一次工业革命,实现了农耕文明向工业文明的进步。电力推动了第二次工业革命,极大的提升了生产效率,人类社会步入了电气时代。在以计算机及信息技术为标志的第三次工业革命,和以人工智能为标志的第四次工业革命中,算力正发挥着越来越重要的作用。未来社会将进入智能世界,人工智能无处不在,无人驾驶进入千家万户,智能机器人,智能家居深刻改变人类的生产与生活,而这一切智能应用的背后需要强大的算力。算力是推动智能世界不断发展的源动力,我们的梦想是打造世界最强算力,成为推动智能世界不断发展的核心力量。
智能世界需要最强算力的产品,那么到底什么是最强算力的产品呢?在通用计算领域,我们认为最强算力的产品应该具备三个基本特征:
多核高并发是普遍需求,因此单个处理器64核应该是起步条件;
实时大数据分析、分布式数据库等场景需要与内存进行大量的数据交换,具备8内存通道是必然选择;
CPU与加速器之间的协同,需要高带宽低时延的I/O,总线能力升级到PCIe4.0是当务之急。

但这还不能完全满足客户对最强算力产品的需求。当前计算架构正从集中式向分布式演进,仅仅CPU有最强算力还不够,我们认为还需要具备多合一SoC、xPU高速互联实现从CPU到服务器的最强算力,以及通过100GE高速I/O实现从单机到集群的最强算力。
我们经常说,汽车跑的快不快,关键要看发动机是否强劲。最强算力的产品必须要有最强劲的处理器。鲲鹏处理器,集成了64个物理核,SPECint评估跑分高达930分,相比业界主流处理器性能提升了25%。鲲鹏处理器除了性能强劲,还采用了多合一的SoC芯片架构,它不仅仅是一颗CPU,还集成了RoCE网卡、SAS控制器、桥片等,单颗处理器实现了4颗芯片的功能,以一当四!可有效提升主板的集成度,使服务器的体积更小,算力密度更高、功耗更低。
华为研发的Cache一致性总线HCCS,可以实现CPU和CPU之间的高速互联,通信速率高达每秒30GT,是业界主流CPU互联速率的2倍多。通过多CPU互联,我们率先实现256个物理核的NUMA架构,从而推出业界首款兼容ARM架构的最强算力4路服务器。异构计算的兴起,使得CPU与NPU之间的互联协议也很关键。华为创新性的将HCCS同样应用于CPU与NPU的高速互联,构建了xPU间的统一Cache一致性架构,xPU之间可以进行直接内存访问,实现高速数据交互。同时基于此架构,可实现通用算力和AI算力的灵活组合,打造最强算力的异构计算服务器。
当前处理器一般通过与外置网卡配合为服务器提供10GE、25GE的接口,在分布式架构下,要完成一个高算力的集群组网,更需要高I/O的吞吐能力。鲲鹏处理器是业界首个推出内置直出100GE网络能力的通用处理器,让100GE成为服务器的标准配置。从处理器到服务器,扩展到整机柜和计算集群,实现全100GE的高速网络互联,引领服务器迈入100GE时代,构建最强算力的集群。
刚才我提到最强算力产品的定义,需要支持多合一SoC芯片架构、xPU高速互联和100GE高速I/O,那么有同时满足这些创新技术的产品吗?答案是:华为TaiShan服务器。TaiShan系列服务器是当前面向大数据,分布式存储,数据库,HPC,原生应用等场景,兼容ARM架构的最强算力服务器。华为提供了存储密集型、计算密集型、边缘计算等多款服务器产品,满足客户从数据中心到边缘的多场景部署需求。
通用计算最强算力标杆鲲鹏主板正式发布并面向合作伙伴全面开放
今天,我将发布一款在计算产业非常,非常,非常重要的产品!

我宣布:鲲鹏主板正式发布,并向合作伙伴全面开放!
鲲鹏主板,搭载两颗鲲鹏处理器,128个物理核,内置100GERoCE;32个内存插槽,支持PCIe4.0;合作伙伴可以基于这块鲲鹏主板,开发出多种形态的计算产品。

华为鲲鹏主板
华为在硬件方面有30多年的研发与制造经验,各种硬件主板出货量累计超过10亿块。鲲鹏主板具备业界领先的56G高速SerDes能力,主板性能提升25%;信号误码率低于10的负12次方,故障率比业界平均水平低15%;我们通过创新的DEMT动态节能技术,可以实现能效比领先业界15%以上。合作伙伴基于鲲鹏主板开发的计算产品,具备高性能,高可靠,高能效的优势,可以100%释放整机算力。
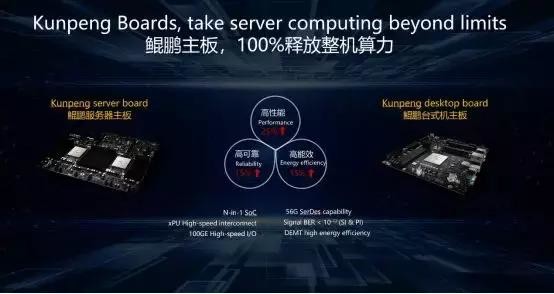
华为面向伙伴开放通用计算能力,优先支持合作伙伴开发更多的最强算力产品
众人拾柴火焰高,华为公司会优先支持合作伙伴,基于鲲鹏主板开发更多的最强算力产品,给客户更多、更好的选择。鲲鹏主板内置了BMC芯片和BIOS软件,我们将开放主板接口规范和设备管理规范。为了提升整机设计效率和质量,华为把多年积累的硬件工程能力开放出来,提供机箱、散热、供电、背板等参考设计指南。此外,我们提供内存,硬盘,网卡,操作系统等软硬件兼容性列表,解决软硬件基础生态配套需求。合作伙伴可以基于鲲鹏主板和整机参考设计,快速开发出自有品牌的服务器和台式机产品。因为你们,我们将变得更好。
基于昇腾910的最强AI算力
除了通用计算,华为还压强投入AI计算的创新,而最强的AI计算又具备哪些关键能力呢?相比于推理,训练芯片的能力更能体现AI的最强算力。华为昇腾910训练芯片基于达芬奇架构,内置了32个3DCube计算引擎,单引擎能够在一个时钟周期内完成4096次乘加运算,算力达到256TFLOPS。基于毫秒级梯度同步及On-Device处理,实现多芯片并行训练。AI服务器搭载8颗昇腾910芯片,算力可达到2PFLOPS。通过Scale-Out扩展可组成大规模的AI集群,结合芯片-服务器-集群通信无阻塞网络技术,集群算力高达1024PFLOPS,将模型训练时间,从数月数周数天,缩短至秒级。
华为发布最强算力的AI训练卡Atlas300与训练服务器Atlas800

在今年8月23日,华为发布了业界最强算力的AI训练处理器昇腾910。今天我将发布两款基于昇腾910的Atlas新产品:算力最强的AI训练卡Atlas300 与训练服务器Atlas800。Atlas是古希腊神话中撑起宇宙的擎天大力神,我们用Atlas来命名AI计算产品,是希望Atlas能够成为撑起智能世界的擎天大力神。
Atlas300,业界最强算力的AI训练卡,可提供256TFLOPS的算力,是当前业界主流训练卡的2倍,每秒训练的图片数量从965张提升到1802张。支持100GRoCE直出高速接口,可实现梯度参数和数据集并行传输,最高可降低70%的梯度同步时延,支撑集群训练时间缩短到秒级。

Atlas800,是业界算力最强的AI训练服务器!Atlas800在仅仅4U空间里集成了8颗昇腾910AI处理器,可提供2PFLOPS的超强算力,算力密度是业界同类产品的2.5倍。Atlas800仅重75千克,不到业界同类产品的一半,内置32个硬件解码器,每秒可完成16384张1080P图片解码,是业界主流产品处理能力的25倍,而且可以与训练并行处理。支持风冷和液冷两种散热方式,满足企业数据中心和集群高密部署两类场景。单机能效是业界同类产品的1.8倍。在华为松山湖的数据中心中,我们已经部署了全液冷的Atlas800 ,单机柜的散热能力高达5万瓦。

昨天,我们发布了全球最快的AI训练集群Atlas900。Atlas900是一个可扩展的AI集群架构,由数千颗昇腾910处理器组成,在ResNet-50测试中,以59.8秒的成绩夺得全球第一,在同等精度下比第2名快15%。Atlas900集群的强大算力,可广泛应用于科学研究与商业创新,比如天文探索、石油勘探等领域。
Atlas全系列产品布局完成,实现全场景部署
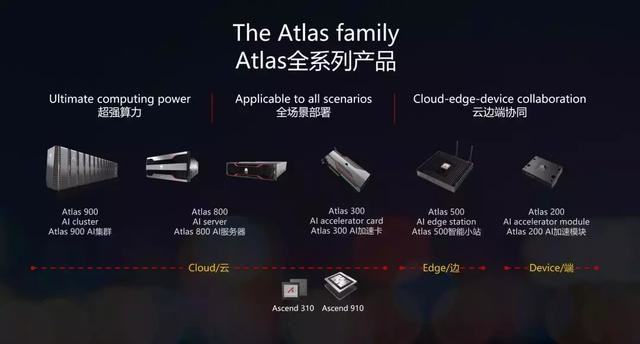
基于昇腾910和昇腾310AI处理器,我们完成了Atlas全系列产品布局,面向训练和推理都提供了超强算力,实现全场景部署。基于统一的达芬奇架构和全场景AI计算框架,实现云边端协同,加速全行业的智能化再造。
今年,华为和南方电网深圳供电局启动了基于Atlas的智能巡检联合创新。屏幕正在播放的是深圳供电局在联合创新前后,高压电线的人工巡检与AI巡检的对比视频。深圳供电局曾经分享过:一名普通线路工人一生巡检走过的山路可绕赤道一圈。山路崎岖,杆塔高耸,工作强度极大,通过基于Atlas的智能无人巡检方案,使得南方电网可以彻底摆脱“一车两人三水壶”的传统巡检模式,实现实时预警,准确上报,更安全,更高效。
技术致善,接力致远,我们希望更多的行业能够通过技术创新,让生命更安全,让社会更美好。




































































