“当前,机器学习采用的还是一些传统处理器架构,比如说CPU,有很多AI负载架构在CPU之上,CPU实际上是一个针对应用和网络设计的处理器,是标量处理器。后来的GPU是针对图形和高性能计算、以向量处理为核心的处理器,从2016年到现在被广泛应用在一些AI应用里。但我们认为,AI是一个全新的应用架构,底层是以计算图作为表征的,所以需要一种全新的处理器架构,而Graphcore IPU就是针对计算图的处理所设计的一款处理器。”Graphcore高级副总裁兼中国区总经理卢涛在接受采访时表示。这也是Graphcore首次在中国详尽阐述其业务布局和发展策略。
Graphcore高级副总裁兼中国区总经理卢涛
英国的布里斯托是IT业重镇,包括NVIDIA、Broadcom、HP在内的多家科技企业均在此设有研发中心。但近几年让这座城市在AI领域被更多人所熟知的,则是2016年在这里诞生的一家明星企业——Graphcore。英国半导体之父、Arm联合创始人Hermann Hauser爵士曾说:“在计算机历史上只发生过三次革命,第一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。”Hermann所指的,就是Graphcore率先提出的为AI计算而生的IPU(Intelligence Processing Unit)。

Graphcore IPU
截至目前,Graphcore累计融资超过4.5亿美元,投资方既有像红杉资本这样的金融投资者,也有像微软、戴尔、三星等战略投资者。如今,Graphcore的全球员工数量约为450人,分布在美国的西雅图、帕洛阿尔托、奥斯汀、纽约,以及亚太地区的北京、上海、深圳、台北、首尔、东京等地,并在伦敦、剑桥分别设立了面向算法研究、以及芯片和底层软件的研发中心。2019年,Graphcore中国成立,总办公室位于北京,同时取了一个颇有意境的中文名称“拟未”。
AI技术的背后是机器的不断进化,直至具备自我思考的意识,这一过程即是机器智能的实现。Graphcore认为,机器智能代表了一种全新的工作负载,其特征体现在大规模并行计算、稀疏的数据结构、低精度计算、数据参数复用、静态图结构和熵。针对AI在落地应用时的解决方案,Graphcore首席执行官Nigel Toon曾做出三类划分,第一类是部署在手机、传感器、摄像头等小型终端中的加速芯片;第二类是ASIC,可以满足超大规模的计算需求,如谷歌的TPU;第三类是可编程处理器,即是IPU所在的领域,这也是GPU发力的市场。
不过区别于CPU和GPU的架构思路,Graphcore为专门处理AI应用从零开始设计IPU——一款高度灵活、易于使用的并行处理器,可用于训练和推理的机器智能模型上实现先进的性能,并且可以支持语言类、CV类、强化学习等各类算法模型。其独特之处在于,Graphcore IPU将整个机器学习知识模型保留在处理器内部,一个服务器内可配置16个与IPU-Link技术连接在一起的IPU处理器,这样的IPU系统拥有超过10万个完全独立的程序,所有程序都在机器智能知识模型上并行工作。
那么Graphcore为什么会想到重新设计一款处理器呢?背后同样是基于AI对计算力的渴求。从算法模型的尺寸来看,从2016年1月ResNet 50的2500万个参数,到2018年10月BERT-Large的3.3亿个参数,再到2019年GPT2的15.5亿个参数,更复杂的算法需要复杂的模型来训练以提升精度,而越来越密集的计算则需要对数以十亿计的参数进行处理,使得计算力要实现指数级增长,已有的计算形态难以满足。
卢涛透露,Graphcore IPU的表现在现有以及下一代的模型上,性能均领先于GPU:在自然语言处理方面的速度提升20%-50%;在图像分类方面,能够有6倍的吞吐量且做到了更低时延;在金融模型方面,训练速度提高26倍以上。
当然,要重新设计一款AI处理器绝非易事,不仅要考虑芯片架构本身,还要提供相关的工具链和软件库支持,以及与主流框架的兼容性,并且要具备友好的可部署性和可移植性。为此,Graphcore在硬件上为AI应用处理设计了IPU处理器,在软件上为IPU处理器构建了POPLAR软件栈和开发工具,在系统解决方案上能够以本地访问或云的方式融合合作伙伴的方案。
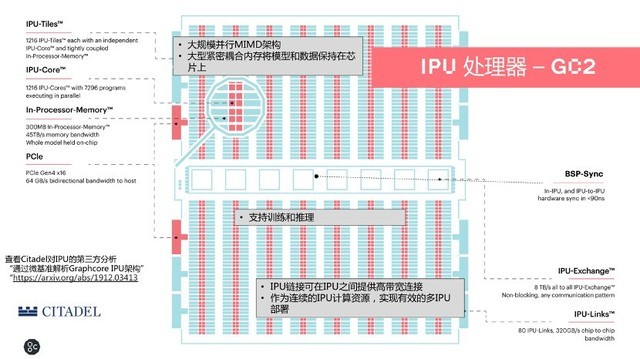
为了打破内存带宽对于算力性能的制约,Graphcore为IPU设计了大规模并行MIMD以满足机器学习所需的高性能和高效率,并且采用大型分布式片上SRAM,在片内支持300MBSRAM,相较CPU的DDR2子系统或GPU的GDDR、HBM来说,能够做到10-320倍的性能提升,时延方面与访问外部内存相比在1%左右。

拥有完整内存访问权限的大规模并行
目前,已量产的IPU处理器GC2采用了台积电的16纳米工艺,融入了236亿个晶体管,拥有7296个线程、16个PCIeGen4,处理器片内包含1216个IPU-Tiles(核心),每个核心均有独立的IPU核作为计算及In-Processor-Memory(处理器内的内存,300MB),内存带宽为45TB/s,每个核心之间可进行BSP(Bulk Synchronous Parallel,常见于大规模数据中心集群)同步,以及跨IPU通信,中间有8TB/s的IPUexchange作为多对多的交换总线。
Graphcore IPU处理器GC2
在IPU和IPU之间,有80个IPU-Links(2.5TB/s),芯片与芯片之间的带宽可达到320GB/s。由此,Graphcore的IPU处理器就可以同时支持训练和推理,并且得益于硬件支持BSP协议,可以把计算逻辑划分为计算、同步、交换,使其具备可编程性,用户也不用再关心任务到底运行在哪一个核上。在120瓦的功耗下,GC2能够实现125TFlops的混合精度。
配合IPU硬件,Graphcore在2019年推出了Poplar软件平台SDK,为框架软件(如TensorFlow、ONNX、PyTorch、PaddlePaddle等)和硬件之间提供了基于计算图的整套工具和库,让开发人员在IPU产品上便捷地运行AI模型。目前,Graphcore已提供750个高性能计算元素的50多种优化功能,支持容器化快速部署及运行,以及Docker、Kubernetes、Hyper-v等技术。借助PopVision Graph Analyser分析工具,开发者和研究人员在使用IPU编程时,可通过可视化的图形展示工具分析软件运行的情况,进行效率调试等操作。操作系统方面,Poplar SDK支持三个主流的Linux发行版:ubuntu、RedHat Enterprise Linux、CentOS。

Poplar开发者文档和社区
据了解,基于IPU的应用已覆盖机器学习的多个领域,包括自然语言处理(BERT)、图像/视频处理(ResNet、ResNext)、时序分析(LSTM、MLP)、推荐/排名(Deep Autoencoder)及概率模型(Markov Chain、MCMC)等场景,并且将源代码在Github上全部开放下载。例如进行BERT训练时,在NVLink-enabled平台上要50多个小时才能做到一定精度,而在基于IPU的戴尔DSS-8440服务器上,36.3小时即可完成。卢涛介绍称:“BERT的推理在同样时延的情况下,IPU能够比当前最好的GPU有高一倍的吞吐量。在MCMC算法上,IPU有26倍的性能提升,在类似于像ResNeXt这种比较新的计算机视觉类应用上,IPU能做到6倍的吞吐量、22分之1的时延。现在一些搜索公司、医疗影像公司的用户都在通过IPU来使用ResNeXt的服务。”
“AI创新者、算法科学家、AI应用开发者通常反馈在日常工作中会遇到两种问题。第一种问题,作为AI应用开发者或产品部门需求者,将需求(包含多低延时、多高吞吐量的指标)提供给算力平台部门时,他们通常会说GPU目前不能够支持这么低的延时、这么高的吞吐量。第二种问题,一个算法模型在GPU上运行的速度非常慢,但处理器架构没有什么问题,因此会想是不是算法出了问题、是不是软件有问题,要优化算法和软件。”卢涛谈到,“通过这幅图可知,如果你的算法模型不是用稠密的卷积,而是用的较为稀疏的卷积比如Fully depthwise,那么你的模型在GPU上运行得不好并不是因为算法不好,而是GPU的架构不符合算法特点,反而IPU能够提供更好的支持。”
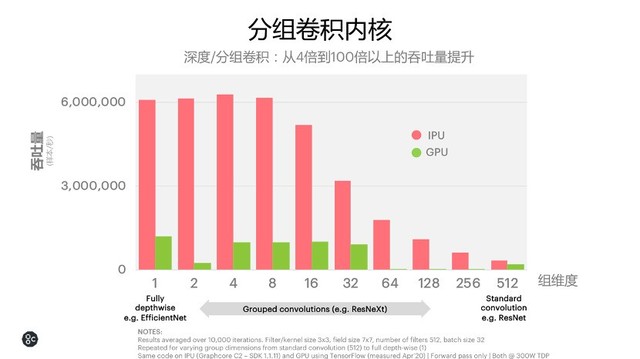
分组卷积内核
为了解决这一问题,Graphcore构造了一个分组卷积内核的micro-benchmark,将组维度(group dimension)分成从1到512来比较,512是应用较多的“Dense卷积网络”,典型应用如ResNet。此时,IPUGC2性能比V100高出近一倍。随着稠密程度降低、稀疏化程度增加,在组维度为1或32时,针对EfficientNet或MobileNet,IPU对比GPU可做到成倍的性能提升,延时大幅降低。MIMD架构使得IPU可以天然适配分组卷积,让算法设计者可以设计出参数规模更小、精度更高的算法模型。

合作伙伴正在加速部署IPU
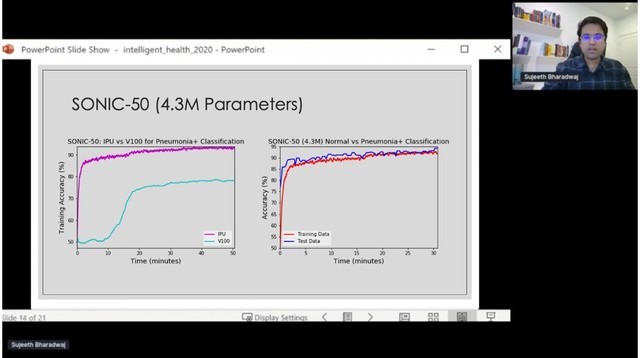
在今年5月27日举办的Intelligent Health峰会上,机器学习科学家分享了如何利用IPU训练CXR(胸部X光射线样片),从而帮助医学研究人员进行COVID-19的快速准确诊断。对此,微软展示了IPU在SONIC CV模型里,30分钟内就能完成传统GPU需要5个小时才能完成的训练工作量。测试过程中,微软先后使用了EfficientNet-B0和改进后的SONIC模型进行训练,后者根据IPU的架构特点进行了优化,包括分组卷积、内核设计等,并由此得到了比EfficientNet更小的模型,该模型有约430万参数。
下图展示了SONIC训练的结果,左边是训练时间。通过IPU和GPU的对比,IPU处在领先位置。右边红色曲线代表训练时精度上升的情况,蓝色曲线代表的是测试精度,图中测试精度和训练精度几乎是吻合的,这表明,SONIC模型在泛化性能上更好,在处理未知的新数据时,表现的会比EfficientNet更好。
SONIC模型测试
测试结果表明,SONIC模型通过30分钟训练可以达到94%的训练精度和测试精度,比GPU训练速度快一个数量级,GPU约需300分钟。微软认为,能够训练到SOTA的精度的模型不一定是大模型,可以用小模型达到精度要求,而且IPU的多指令、多数据架构也非常适合以分组卷积为代表的新模型。目前,微软正采用IPU进行计算机视觉方面的训练,并尝试把IPU在CV领域的应用扩展到监测、分割、配准等更多方面。
在行业场景中,Graphcore IPU在金融、医疗和生命科学、电信、机器人、互联网、云和数据中心等领域均有较为深度的应用。例如在金融行业的算法交易、投资管理、风险管理、诈骗识别等方面,IPU在金融建模时的训练和推理均有其独特性,包括决策时延迟更低、试验模型架构时迭代速度更快、使用概率模型避免过度拟合并解释噪声、持续再训练等。
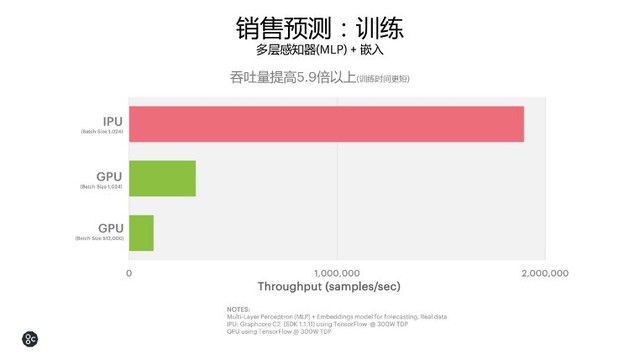
销售预测
“在金融领域,IPU能够给大家带来更快、更智能的未来,表现在低延迟情况下可以把性能和吞吐量大幅提升。另外在金融领域有一些是不可向量化的模型,如果这个模型不能向量化的话,就意味着在GPU上无法运行,或者说性能非常差。对于这一类模型在IPU上反而能取得非常好的效果,使得这个模型的落地变为可能。”Graphcore中国销售总监朱江说。

Graphcore中国销售总监朱江
在电信领域,机器智能可以分析无线数据的变化,Graphcore采用LSTM模型预测性能促进网络规划。基于时间序列分析,采用IPU比GPU有260倍以上的提升。再如5G网络切片时需要大量学习没有标记过的数据,属于强化学习的范畴,IPU运行强化学习策略在训练方面的吞吐量能够提高最多13倍。
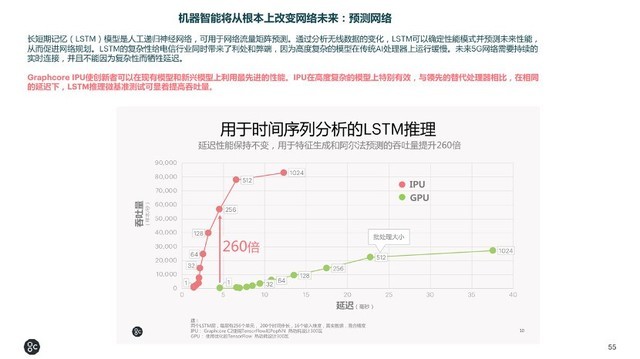
用于时间序列分析的LSTM推理
AI领域的推理和训练市场都在快速增长,如果把推理市场进一步细分,会发现当前比较流行的Int8甚至是以后的Int4并不具有普适性,像应用规模较大、主流的CV类模型是以Int8为主,然而像NLP模型,以及一些搜索引擎用的模型或是广告算法模型,却是以FP16、FP32为主流的数据格式,这类模型对精度的要求更高,需求量同样很大。目前,Graphcore的IPU处理器并不支持整数(Int8),但支持FP16/32混合精度。
“未来,我们的推进策略还是训练和推理并行,会更加聚焦那些对精度要求更高、对时延要求更低、对吞吐量要求更高的场景。”卢涛表示,“另外,我们现在看到一个大趋势,就是训练和推理可能有混布的需求。举两个例子,一个是像线上的一些推荐算法,譬如说视频平台或电商网站希望能够通过算法同时进行训练和推理,然后根据用户的数据实时地更新算法模型。还有一个例子就是汽车类应用。”
在5月12日举办的OCP Global Summit上,阿里巴巴异构计算首席科学家张伟丰博士宣布了Graphcore支持ODLA的接口标准。之后的5月20日,在百度Wave Summit 2020上,百度集团副总裁吴甜宣布Graphcore成为飞桨硬件生态圈的创始成员之一,双方签署了倡议书。近期的一系列合作标志着Graphcore正在积极融入中国的AI生态圈,加速支持中国本土的机器学习框架。
卢涛谈到,Graphcore对其在中国市场的发展有着非常高的期望,希望未来中国市场能够在Graphcore全球市场中占到40%-50%的份额,“中国更加重视AI应用落地,更看重产品化的训练和推理,更侧重于利用AI解决具体的场景和应用问题。我们会针对中国市场的需求,对产品进行定制化。目前,我们有两支技术团队,一支是以定制开发为主要任务的工程技术团队,另一支是以对用户技术服务为主的现场应用团队。其中,工程技术团队承担两方面的工作,一是根据中国本地的AI应用特点和需求,把AI算法模型在IPU上进行落地;二是根据中国本地用户对于AI稳定性学习框架平台的软件需求,加强功能性开发。”

本文属于原创文章,如若转载,请注明来源:GPU的颠覆者 Graphcore如何重新定义AI计算架构?//cloud.zol.com.cn/746/7468110.html