“在图形运算平台上,NVIDIA已耕耘超过20年的时间。NVIDIA是GPU发明者和全球图形运算行业的领袖,也是全球AI计算的先锋企业。在过去20年里,NVIDIA在各式各样的图形和可视化运算及AI等不同领域,都针对我们的GPU做了相对优化。”NVIDIA中国区高级技术市场经理施澄秋表示,“我们的GPU无论是在软硬件设计,还是功能改进,每一代都针对不同用户(电视、娱乐、传媒、现场直播、汽车制造、设计、大数据运算、科学运算、专业电影制作、AI等)产生了不同性能飞跃,包括现在很流行的AEC、BIM、CAM等等,只要想到NVIDIA产品,就能想到在这些行业里面都可以利用NVIDIA产品的优势带来各式各样的性能体验飞跃。”
近年来,NVIDIA在专业视觉计算领域进展快速,从Kepler到Maxwel、Pascal、Turing、再到当前的Ampere架构,在显存技术、规格和软件运算规格,以及支持5K、8K、VR/AR等一系列的软硬件及环境配套支持方面,均提供了高质量的支持。最新发布的基于NVIDIA Ampere架构的NVIDIA RTX A6000和NVIDIA A40,采用了全新RT Core、Tensor Core和CUDA Core加速图形、渲染、计算和AI,较上一代产品增速显著,为专业人士提供了新的选择。
NVIDIA RTX A6000

NVIDIA A40
结合3D仿真模拟和协作平台Omniverse(公测版),使得NVIDIA在图形、仿真、AI取得了新的突破,该平台融合了物理和虚拟世界,能够实时模拟出细节逼真的现实世界。远程团队可以通过该平台同时开展项目协作,例如负责3D建筑设计迭代的建筑师、修改3D场景的动画师以及协作开发自动驾驶汽车的工程师,整个协作就像是在线上共同编辑文档一样简单。
相比第一代RTX GPU的Turing架构,Ampere架构提供了第二代RTX GPU,搭载新一代的SM(新一代流式多处理器)架构最高可以提供39 TFLOPS的FP32算力。第二代RT Core最高可以提供76 TFLOPS光线追踪算力,具有两倍于上一代的吞吐量,支持并行光线追踪、着色和计算功能,同时加入了第三代Tensor core,可提供5倍于上一代的吞吐量,支持TF32和BF16数据格式,结合稀疏运算特性提供10倍加速性能,算力至多能达到310个Tensor TFLOPS。基于Ampere架构,A100尽可能多的部署了Tensor Core计算核心,GA102则在Tensor Core的基础上配备了RT Core。
SM中对FP32精度的两倍吞吐量提升可以更好的支撑图形运算、物理模拟等场景,考虑到这些应用对于精度的要求没有那么苛刻,为了提升工作效率和每瓦特性能(性能功耗比),通常会采用单精度浮点运算,且Ampere架构有着两倍运算速度的提升。使用过程中,用户只需对FP32进行小幅修改就能直接适应TF32,大幅降低运算量。同时,稀疏算法和基于稀疏式的硬件结构也使得推理性能的吞吐量翻倍。
第二代光线追踪运算核心对BVX算法做了大量优化,包括Motion flow、阴影功能、去噪点、降音功能等特性。由此,可以把此前需要分开处理的流程,或是由不同核心、不同周期处理的任务,合并在一起工作以整体提升工作效率。据悉,NVIDIA针对“运动模糊”的渲染中加入了很多独家算法,让在实时光线追踪加持下的Motion flow能够更有效率。除此之外,NVIDIA RTX A6000还支持全新DDR6显存,与NVIDIA A40一同支持48GB GPU内存,通过NVLink连接两个GPU可扩展至96GB。当然,两款新品也会支持PCle Gen4,提供两倍于上一代的带宽,可以加速Lenovo ThinkStation P620等PCIe Gen 4服务器和工作站中数据密集型工作负载(如数据科学、混合渲染和视频流)的GPU数据传输。
借助NVIDIA RTX A6000和NVIDIA A40,专业人士可以在关键应用中获得性能提速,大幅提升工作效率。Predator Cycling公司使用RTX A6000配合Keyshot、ANSYS CFD、Fusion360等专业软件,在车辆的设计和制造环节利用GPU加速实现了2-6倍的性能提升,能以视频会议的形式在不同团队之间共享GPU渲染效果,协同工作。在建筑工程设计行业,对于BIM模型管理过程中所涉及的风控、现场管理、管线配备,或是基于光线、流体力学等负载,48G显存的GPU能够提供所见即所得的应用体验。
全球最大的建筑事务所之一Kohn Pedersen Fox Associates是最早一批使用RTX A6000的公司。该事务所表示该GPU能够将分辨率提高至原来的3倍,并加快复杂建筑模型的实时可视化。KPF的可视化经理Paul Renner表示:“NVIDIA RTX A6000的惊人之处在于能够将分辨率提高至原来的2倍或3倍,并显著加快城市景观中大型复杂建筑模型的实时可视化速度。”
一直以来,NVIDIA Quadro系列都是媒体和娱乐行业的重要推手,基于AI的面部实时追踪、人脸识别等功能,以及高保真的工作流程和渲染等特性为用户带来了栩栩如生的观感体验。DOMAIN与NVIDIA合作已久,其利用Epic引擎和NVIDIA GPU不断进行技术突破,让“数字人”的实时光线追踪、机器学习、深度学习等技术实现了前所未有的逼真和复杂度。在AUTODESK ARNOLD中,RTX A6000结合针对Motion Blur的AI算法,可让“运动模糊”在关闭/开启时的性能分别提升两倍和3.5倍。
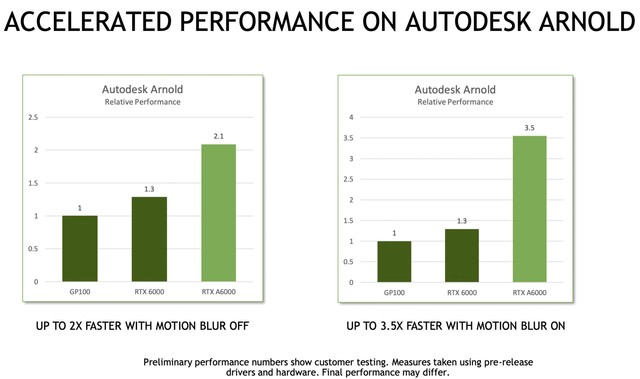
AUTODESK ARNOLD性能加速
“我们可以利用NVIDIA Ampere架构的GPU,直接存取磁盘、SSD、硬盘上的数据,而不需要像以前一样通过CPU调度、系统总线、系统主内存进行交换。”施澄秋介绍称,“我们能用GPU的功能去交换磁盘性能,无论是稀疏性,或者引入FP32单精度模式获得五倍的吞吐性能,还是利用新一代总线技术和数据管理技术,A6000对于大体量数据交换和AI所需要的源源不断的数据供给,以及针对科学运算、科学数据大数据交换的应用场景,都可以获得新一代Ampere架构GPU带来的高性能。”
满足AI和数据科学场景需求
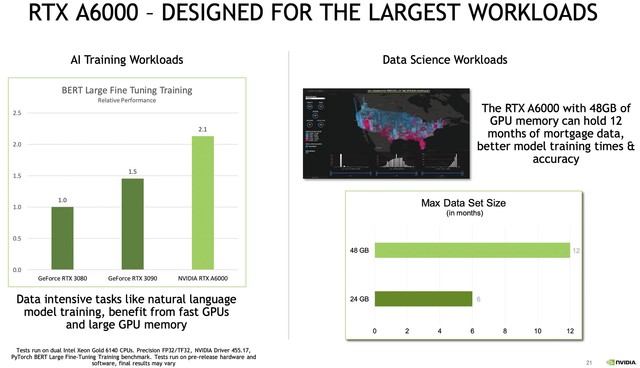
应对最大规模工作负载
相较于RTX A6000,支持“被动散热解决方案”的A40更适合对功耗、噪音、管理便捷性有着更高要求的客户。A40可应用于机架式服务器,同样可以很好的支持视觉运算、超算,以及仿真、虚拟工作站、3D设计、VR、虚拟生产、光线追踪等场景,更适合集群式数据中心使用。A4可以同时满足AI运算、图形计算的多种需求,并且能够进行虚拟化部署。通过将两块A40和两路NVLink堆叠,至多可提供96G显存,满足大规模复杂场景和运算模型数据集的调用。
获得奥斯卡奖的英国动画和视觉效果公司Framestore借助全新的RTX A6000、HP ZCentral和NVIDIA Omniverse在远程工作站环境中,对海量数据集进行实时光线追踪。在GTC 2020秋季站上,NVIDIA发布了公测版Omniverse。抢先体验项目期间,爱立信、Foster + Partners、工业光魔(ILM)和其他40多家公司,以及400位个人创作者和开发者对该平台进行了评估并向NVIDIA工程团队提供了反馈。Omniverse基于皮克斯应用广泛的Universal Scene Description(USD),一种能够在3D应用中实现通用互换的先进格式。该平台还使用了多项NVIDIA技术,例如实时照片级逼真渲染、物理效果、材质,以及在3D软件产品之间的交互式工作流程。
对于机器人、汽车、建筑、工程与建设、制造、媒体和娱乐行业的客户来说,Omniverse所能实现的协作和仿真模拟至关重要。过去,这些用户在UE虚幻引擎、AUTODESK REVIT、SUBSTANCE by Adobe、Unity、MAYA等第三方平台,调用NVIDIA的光线追踪、毛发、粒子、物理模拟、VR/AR等特性时,往往要在不同的平台上完成不同的工作,还要涉及繁琐的数据资产存取/导入/导出和格式切换等问题。
“Omniverse是一个跨软件、跨应用程序的在线合作式/分享式总体解决方案平台。”施澄秋说,“借助NVIDIA Omniverse平台,无论用户使用什么软件、工具和平台,都能通过NVIDIA Omniverse这个入口,帮助分发协调工作、整合工作流程,让所有用户、设计师、科学家和工程人员都在同一个NVIDIA Omniverse平台上完成分工和协作。”此外,这个平台还可以利用NVIDIA各式各样的软件堆叠,包括物理加速、材质描述库、MDL语言,以及NVIDIA和PhysX合作的USD通用场景描述语言,存取数据资产让各式各样的第三方ISV、软件专业工具程序进行调用。

NVIDIA Omniverse平台
例如NVIDIA在Omniverse平台上使用USD,通过开放的API支持复杂的场景贴图,在千差万别的应用程序之间帮助互换数据资产。同时,它还能够分层式管理数据资产,让许多不同部门的大型团队在同一个场景工作并共享数据,从而进行协同和分布。在虚拟世界训练自动驾驶汽车时,会面临复杂的路况和天气条件,Omniverse则可以把虚拟数据交给车载计算机,后者把虚拟世界创造的3D场景认成车载雷达感知到的真实世界场景,被训练后做出真实反馈。
施澄秋谈到,Omniverse平台可以同时支持离线渲染和实时渲染,原因是Omniverse的后台拥有大量可堆叠、多节点的GPU渲染器,或者DGX服务器,具备超级计算机的计算能力,可以为专业图形渲染提供强大且源源不断的动力,“借助高端的RTX GPU,我们无需在速度和性能之间做妥协,Omniverse可以让用户‘鱼与熊掌’兼得,实现实时反馈以及高品质的渲染。”
与上一代产品相比,NVIDIA Ampere GPU架构提供的性能优势,配合Omniverse的协作和仿真模拟能力,为专业人士提供了前所未有的体验。未来,随着5G、AI、边缘计算等技术走向行业纵深,各行各业对现代化生产力的需求将与日俱增,而NVIDIA所提供的强劲算力,也势必会在专业可视化领域持续带来耳目一新的用户体验。

本文属于原创文章,如若转载,请注明来源:任意平台实时协作 NVIDIA在专业可视化的飞跃式创新//cloud.zol.com.cn/758/7584307.html