数据的指数级增长让计算步入了百亿亿次的时代,越来越多的计算任务除了对高性能有着源源不断的需求,对于弹性、灵活性和安全性同样关注。当前,针对数据模型的参数训练已经达到5000亿的级别,数据中心的算力增长显而易见,而云技术的加入则让算力供给更为灵活,使得用户可以按需索取,省去了物理设备的安装、运营和维护成本。与此同时,云原生架构也能够让服务过程更加安全可靠。
不过,要想把云原生超算带入成千上万的数据中心并非易事,首要解决的问题就是网络连接,InfiniBand被认为是主流选择,原因有四个。第一,无论是在网卡、DPU还是交换机上,InfiniBand可以根据不同的业务模型和通信模型支撑相应的引擎;第二,InfiniBand网络可以轻松扩展至数万到数百万节点,支持不同的拓扑方案而无需担心出现死锁和网络风暴的情况,动态路由能够大幅提升网络利用效率;第三,在InfiniBand网络中可由软件定义规则,在执行规则时由InfiniBand的硬件实现,让网络管理更加高效,即插即用的特性免去了对硬件的设置过程;第四,InfiniBand是业界标准的面向高性能计算和存储的网络,适用于云原生的架构。
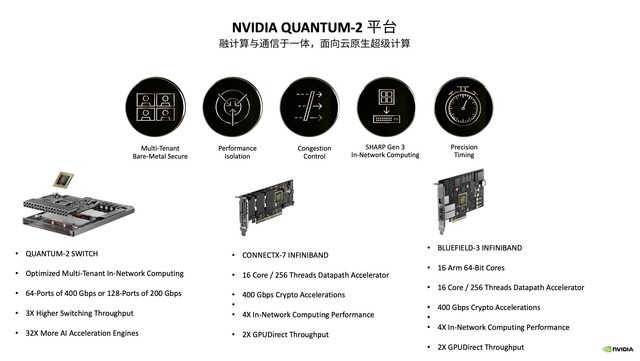
此前,NVIDIA推出了NVIDIA Quantum-2——新一代InfiniBand网络平台,该平台即400Gbps的InfiniBand网络平台,包括NVIDIA Quantum-2交换机、ConnectX-7网卡、BlueField-3 DPU,以及支持这种新架构的软件。由此,NVIDIA在云原生层面提供了一系列关键功能:多租户、性能隔离、拥塞控制、超高精度计时等。Quantum-2对多种通信模型进行了优化,例如点对点模型,可以通过MPI Tag Matching对通信性能大幅度优化,还有MPI业务或AI业务中会用到All-to-All通信,在InfiniBand网络中加入了All-to-All offload Engine,大幅提升了All-to-All通信时的通信效率。Quantum-2平台还增加了PDA(Programmable Datapath Accelerator),可以对特定流量进行编程和加速,通过InfiniBand和DPU做更多的延伸。
NVIDIA Quantum-2平台
Quantum InfiniBand的动态路由技术可以根据网络拥塞的状况自动选择更畅通的道路传输数据,通过动态路由技术让通信效率达到96%以上,远高于以太网。与传统超算独立运行单一任务不同,云端的超算会并发运行多个任务,彼此之间会相互干扰导致执行任务时间延长,而动态路由+InfiniBand拥塞控制技术,就可以让业务在云上和在传统HPC环境、Bare-metal环境下的性能完全一致。具体来说,拥塞控制会把网络中不同的业务识别出来,当某一个业务可能会导致网络拥塞的时候,会预先采取措施把有可能导致网络拥塞的业务速度压下来,让它在往网络中发送数据时不会影响网络端口的缓冲。
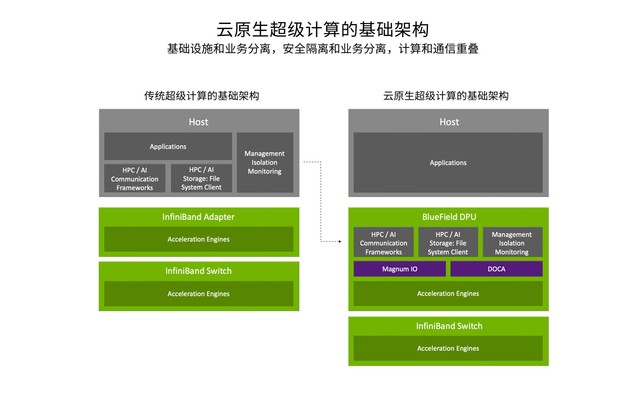
云原生超算的基础架构
超算上云的另一个推动力是CPU、DPU、GPU的3U一体云原生架构,其中融合了计算与通信的BlueField DPU为此奠定了基础。DPU实现了新的云原生计算架构,可以执行通信框架、存储框架、安全框架和业务隔离,让主机里面的CPU和GPU资源都释放给应用,借助该架构可让业务性能得到充分发挥,甚至比在裸机中还要好。计算与通信结合之后,可以用DPU加速HPC业务中的通信,由DPU运行通信框架,由CPU和GPU执行真正的浮点运算。例如在RDMA读写操作时,可以由DPU直接对主机CPU的内存发起,在后者不感知的情况下读取数据或是把数据写到CPU的Memory中,实现通信和计算的重叠,同时DPU再配合通信框架可以智能识别通信时消息的大小,以此来选择不同的优化方式。由此,MPI iAlltoall的性能可以提升44%,MPI iAllgather的性能可以提升36%,需要做快速傅立叶变换的业务性能可以提升近30%。
“在Quantum-2平台, 通过网络计算技术为业务提供了很多的优化空间,比如可以把OpenStack、OVS、Openshift这些操作运行在DPU的ARM CPU上,这样就能把基础设施domain和业务domain分开,让业务domain不会受到其他操作的影响,降低长尾延迟。通过在HOST网卡、DPU和交换机上添加不同的计算引擎,可以对各种不同的业务进行加速,并且让业务运行更安全,进一步提升业务性能。”NVIDIA网络事业部亚太区市场开发高级总监宋庆春表示,“可以说,DPU的出现来弥补了在数据中心中对于基础设施加速能力的不足,实现了DPU、GPU、CPU的3U一体新型架构,让数据中心成为新的计算单元,通过DPU、CPU和GPU的分工协作实现了数据中心中最优的性能。”
安全性方面,NVIDIA云原生软件定义安全技术构建了零信任环境下的防护屏障。随着非结构化数据、跨平台业务、复杂模型的快速增长,如果用传统的安全工具应对现代数据中心的风险,发现漏洞可能需要半年的时间,修复时间超过两个月,造成的影响可想而知。此前,NVIDIA曾推出零信任网络安全平台,该平台结合了三种技术——NVIDIA BlueField DPU、NVIDIA DOCA和NVIDIA Morpheus网络安全人工智能框架。开发合作伙伴通过该平台可实现应用程序与基础设施隔离,增强下一代防火墙的性能,并利用加速计算和深度学习的力量来持续监控和检测威胁,从而大幅提高数据中心的安全性,而这一切的处理通过NVIDIA加速性能比普通服务器快600倍。
DOCA 1.2提供了其他高级零信任安全功能,可作为库及容器化服务,其中包括软件和硬件认证、硬件加速的线速数据加密、对分布式防火墙和智能遥测的支持,以及策略执行,如基于角色的访问控制和微服务、租户之间的安全隔离等。在DOCA 1.2中,内置负载均衡、DPI、 IPS、IDS、下一代防火墙等功能,安全软件供应商可以直接通过DOCA的API调用GPU中的硬件加速引擎。
通过NVIDIA BlueField DPU的强劲硬件加速引擎,使企业能够同时检查其数据中心网络中的所有遥测数据。Morpheus是一个由加速计算增强的基于深度学习的网络安全框架,NVIDIA Morpheus的最新版本包括一个新的工作流程,该工作流程使用无监督学习来创建数字指纹,以检测网络入侵者何时接管用户帐户或机器。为了在潜在威胁恶化之前识别出它们,Morpheus会监控来自不同来源的流式遥测数据,包括BlueField DPU、网络流量、应用程序和云日志,可以实时分析每个用户、机器和服务产生的细微数据中心特征的异常,然后立即提醒安全运营团队。
“通过NVIDIA DPU可以对数据进行100%加密,这样可以在传输数据的时候,对所有的数据都做加密,即使有一个数据不小心忘了加密,Morpheus很快就能侦测出来,还可以跟踪数据到达过的任何地方,跟未经加密的数据任何有关联的事件都会被Morpheus抓出来,同时它会推荐下一步应该怎么做。Morpheus可以追踪网络中所有的异常行为,这就是利用了AI深度学习的能力再加上DPU的硬件加速执行单元。因此,Morpheus相当于是一个发号施令的单元,最后的执行都会落在NVIDIA DPU上。”宋庆春介绍称。
目前,NVIDIA的以太网、InfiniBand网络(UFM Cyber-AI)均与Morpheus深度整合,能够对网络异常行为进行识别和处理,以及对未来网络可能出现的异常情况进行预测和防护。例如会根据网络应用特征进行训练,生成针对不同应用的模型,当某天发现运行这个应用时的特征与模型特征不匹配,就会向管理员发出警告,建议其检查网络异常。如果有潜在可能发生问题的点,就可以先把那些点规避或替换掉,使得数据中心不用再等到问题发生后再修复,而是提前就能及时把问题杜绝。
DOCA 1.2的IPSec和TLS加密可以在400G、200G、100G的环境下以网络限速对所有数据包做加解密,并且能够对所有的链接进行跟踪,发现数据中的任何问题。如果某个数据本来应该加密但没有加密,DPU也可以快速侦测出来,之后把信息通知给Morpheus,二者协作把受未加密数据影响的所有点都会查出来。调用过程中,DOCA 1.2为开发者提供了针对IPSec、DPI等操作的标准API以便快速接入。

DOCA 1.2支持零信任
NVIDIA BlueField DPU卸载了CPU运行安全软件的负担,并使开发人员能够使用DOCA 1.2的新网络安全功能建立量化的云服务来控制资源访问、验证每个应用和用户、隔离可能受到影响的机器并帮助保护数据免遭破坏和盗窃。DOCA 1.2零信任安全框架则是驱动NVIDIA BlueField DPU的基础软件。NVIDIA BlueField DPU可以卸载、加速和隔离数据中心基础架构任务。如同NVIDIA CUDA使开发者能够构建基于NVIDIA GPU的应用,DOCA使开发者能够基于BlueField DPU构建软件定义、硬件加速的网络、安全、存储和管理应用。
据了解,德克萨斯农工大学高性能计算中心会成为首批接入NVIDIA Quantum-2 InfiniBand平台的机构之一。其ACES超级计算机由戴尔科技建造,将使用400G InfiniBand网络为研究者连接来自四家厂商的五个加速器。密西西比州立大学也将使用NVIDIA Quantum-2 InfiniBand平台,这是构建Orion新系统的首选网络,Orion是密西西比州立大学管理的四个集群中最大的一个集群,这四个集群全部使用较早版本的InfiniBand网络所构建。
在英国,莱斯特大学的数据密集型超级计算机DIaL系统已经升级到200G版本的NVIDIA Quantum InfiniBand。DIaL是英国DiRAC设施中使用InfiniBand的四台超级计算机之一,另外还包括爱丁堡大学的Tursa系统。在一次技术评估中,研究人员发现与使用另一种互连方式的纯CPU系统Tesseract相比,在由Quantum网络和NVIDIA GPU加速器构建的Tursa系统上运行应用可提升五倍性能。基准应用测试显示,Tursa系统上16个节点的性能是Tesseract系统上512个节点性能的两倍。Tursa系统的每个节点提供10 TFlops计算性能,使用90%的网络带宽,每千瓦性能相比Tesseract有显著的提高。
Atos公司将利用NVIDIA基于Arm架构的Grace CPU、NVIDIA下一代GPU、Atos BXI E级互连技术和NVIDIA Quantum-2 InfiniBand网络平台,开发一台E级计算级别的BullSequana X超级计算机。Atos和NVIDIA联合成立的卓越人工智能实验室(Excellence AI Lab,EXAIL),将利用Atos的计算解决方案和NVIDIA Clara,帮助医疗研究人员和供应商利用嵌入式、边缘、数据中心和云平台,加速药物研发并设计先进的诊断解决方案。此外,EXAIL研究团队将利用NVIDIA Morpheus开放式AI框架,开发一个新的数据中心到边缘的零信任网络安全平台,以及新的人工智能模型,即时检测新的网络安全威胁。
随着数据中心对算力的需求日益增长、数据和模型的并行训练成为趋势,云原生技术将对兼顾高性能和安全性发挥更大的作用,即使是推理过程也会随模型增大而变得更复杂,走向分布式的时候需要更强的算力和通信能力。当AI成为数据中心的主流应用之一,算力逐渐演化为一种资源和服务,以云原生的方式来实现更低的功耗、更高的性能可谓是一个重要的方向。
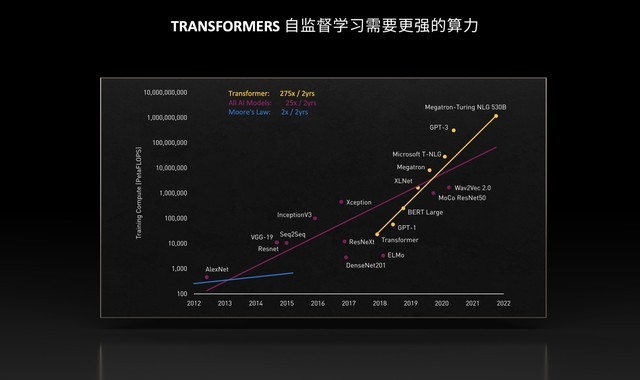
Transformers自监督学习需要更强的算力

多GPU和多节点推理时代已经到来
“最初的数据中心通常用于运行关键的单一任务,后来软件定义数据中心的出现,使得数据中心可以运行多个业务,不过由此也发现如何优化利用资源成为瓶颈。之后又有了新的技术,通过SDN、数据中心解耦、微服务可以解决资源利用的问题,但是如何提升扩展性?数据中心由南北向扩展走向了东西向的扩展,横向走过来,算力就成为了瓶颈。”宋庆春谈到,“NVIDIA的GPU方案解决了算力的瓶颈,网络方案解决了扩展效率和数据中心协同的瓶颈,但性能隔离和安全性等新的问题又该如何解决?这就需要NVIDIA DPU,所以说,CPU、GPU、DPU的3U一体缺一不可,这是数据中心成为计算单元的基础,也是算力成为服务的基础。”



本文属于原创文章,如若转载,请注明来源:云原生推动HPC加速变革 AI计算开启数据中心新纪元https://cloud.zol.com.cn/783/7835601.html